Multiplication operations are complex for a hardware designer. So, optimisations in multipliers are always a good thing to do when we design hardware. Vedic mathematics methods are very efficient in terms of area and delay for hardware design. A simple 4×4 multiplier using Urdhva-Tiryagbhyam method is presented here. But, note that this method is efficient only when the bitwidth of the operand is less than 8-bit.
Line notation of Urdhva-Tiryagbhyam:
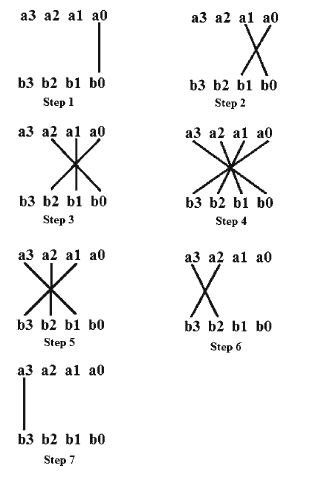
Calculation:
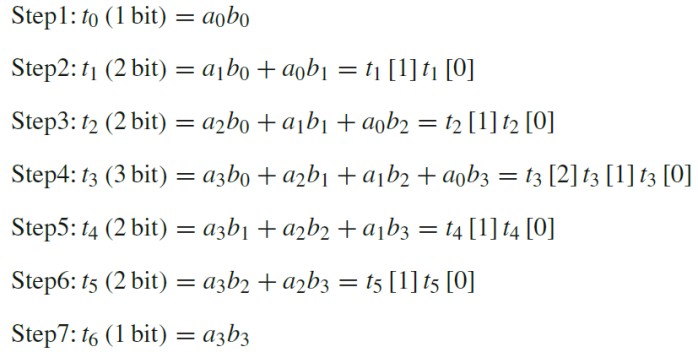
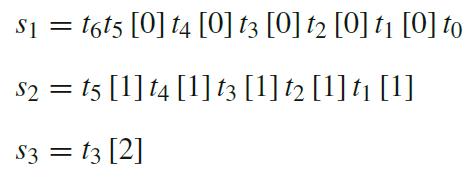
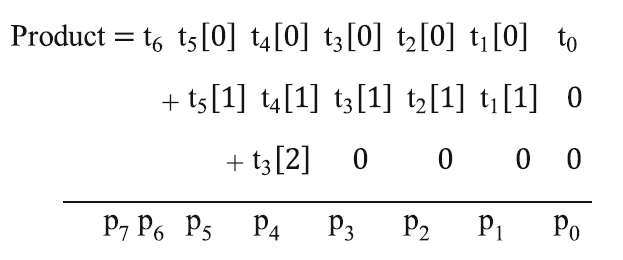
module UT_4x4_mul(
a,b, //4-bit inputs
product, //8-bit output
clk
);
input clk;
input [3:0] a,b;
output reg [7:0] product;
reg G00,G01,G10,G11,G02,G20,G30,G21,G12,G03;//AND gates
reg G31,G22,G13,G32,G23,G33;
half_adder A1_HA(.a(G10),.b(G01),.sum(p1),.cy(c1),.clk(clk));
adder_4_to_2 A2_A42(.a(c1),.b(G20),.d(G11),.cin(G02),.sum(p2),.cout(c2),.clk(clk));
adder_5_to_2 A3_A52(.a(c2),.b(G30),.d(G21),.e(G12),.cin(G03),.sum(p3),.cout(c3),.clk(clk));
adder_4_to_2 A4_A42(.a(c3),.b(G31),.d(G22),.cin(G13),.sum(p4),.cout(c4),.clk(clk));
full_adder A5_FA(.a(c4),.b(G23),.cin(G32),.sum(p5),.cout(c5),.clk(clk));
half_adder A6_HA2(.a(c5),.b(G33),.sum(p6),.cy(c6),.clk(clk));
always@(posedge clk)
begin
G00<=a[0]&&b[0];
G01<=a[0]&&b[1];
G10<=a[1]&&b[0];
G11<=a[1]&&b[1];
G02<=a[0]&&b[2];
G20<=a[2]&&b[0];
G30<=a[3]&&b[0];
G21<=a[2]&&b[1];
G12<=a[1]&&b[2];
G03<=a[0]&&b[3];
G31<=a[3]&&b[1];
G22<=a[2]&&b[2];
G13<=a[1]&&b[3];
G32<=a[3]&&b[2];
G23<=a[2]&&b[3];
G33<=a[3]&&b[3];
product={c6,p6,p5,p4,p3,p2,p1,G00};
end
endmodule
module half_adder(a,b,sum,cy,clk);
input a,b;
input clk;
output reg sum,cy;
always@(posedge clk)
begin
{cy,sum}=a+b;
end
endmodule
module full_adder(a,b,cin,sum,cout,clk);
input a,b,cin;
input clk;
output reg sum,cout;
always@(posedge clk)
begin
{cout,sum}=a+b+cin;
end
endmodule
module adder_4_to_2(a,b,d,cin,sum,cout,clk);
input a,b,d,cin;
input clk;
output reg sum,cout;
always@(posedge clk)
begin
{cout,sum}=a+b+d+cin;
end
endmodule
module adder_5_to_2(a,b,d,e,cin,sum,cout,clk);
input a,b,d,e,cin;
input clk;
output reg sum,cout;
always@(posedge clk)
begin
{cout,sum}=a+b+d+e+cin;
end
endmodule
